0.5008030838419532 Baseline: gotta start somewhere
We’ll start simple. So simple you may wonder if it’s AI at all. When building models from scratch, I like to start with the easiest thing possible and iterate. Before we write any code, let’s define what machine learning and machine learning models are.
2.1 What is machine learning?
Machine learning is a field of artificial intelligence focused on algorithms that 1) learn from data and 2) generalize to unseen data. There are three main components to machine learning, data, models, and algorithms. Machine learning models are the things that do the learning and the algorithms direct the models learning. The lines blur at times between models and algorithms and some algorithms only work for some models. At their core, models are functions. They take an input, process them in some way, and return an output. Models have learnable parameters and machine learning algorithms focus on adjusting these parameters to make the model produce better outputs.
Conceptually, models are simple. Take the equation for a line, f(x) = m*x + b. This is a model where m and b are constant values indicating the slope and y-intercept of the line. x is an input value and the output is f(x) = y. If we know m and b we can compute y for any x. Machine learning comes to the rescue when we don’t know m and b. Assuming we have a bunch of (x, y) points, a machine learning algorithm can guess what good values for m and b are based on those points. Then we freeze those values and the model can predict y for any x.
Models can be giant equations and it’s easy to get lost in the details, but remember it’s still just an equation! The learning algorithm will find the right constant terms for us. It’s our job to set up the problem for the algorithm and model and then get out of the way so the machine can learn.
Note
In machine learning, the constant terms of the equation are called parameters or weights. During training they are not constant as the learning algorithm is trying to find their optimal values, but once training is done these values become constant and you’re left with a normal equation.
2.2 The simplest of models
Turning our attention back to our model, the simplest thing we can do is predict the same thing for every input. And if we’re going to predict the same thing for every input, it should be the most common thing.
This may seem silly, but it gives us a measuring stick to compare to other models. If we use the latest and greatest techniques in deep learning, it should outperform this model. The only way we’ll know it outperforms it is by building the model and testing it. If it doesn’t outperform this model, that raises cause for concern and the results should be investigated. So we start simple and incrementally improve until we are satisfied.
2.4 Metrics, metrics, metrics
Metrics give a sense of how well your model is doing. They allow you to measure and compare models. There is no one size fits all metric, and you’ll usually want to look at multiple metrics when evaluating models. I recommend starting with the end when picking metrics. Why are you building this model in the first place? What is it you want the model to do? Then define your metrics with that objective in mind.
2.4.1 Accuracy
We are trying to predict the sentiment of movie reviews. We don’t care about positive vs negative, we just care that we get it right. It’s a simple question, “How many predictions are correct?” This is accuracy. It’s measured as a ratio, the number of correct predictions over all predictions.
import numpy as np
def accuracy(y, y_pred):
# Convert to numpy arrays for convenience.
y, y_pred = np.array(y), np.array(y_pred)
# Create an array of boolean values indicating if
# `y` and `y_pred` are the same at each index.
is_equal = y == y_pred
# Sum the `True` values.
correct = np.sum(is_equal)
# Return the ratio of correct over total.
return correct / len(y)
accuracy([0, 1, 1], [1, 1, 1])np.float64(0.6666666666666666)In the simple example above there are two lists where the difference between them is at the first element. Two out of three are the same and that’s exactly what accuracy tells us.
In practice, we don’t have to write our own accuracy function because scikit-learn offers one.
np.True_Back to our classifier! When we ran cls.score(X, y), the model returned the accuracy. We can check this by computing the accuracy ourselves.
(0.500803083841953, 0.500803083841953)Our accuracy is 0.5 out of 1.0, or 50% , which means we got half of the predictions correct. This makes sense since our dataset is half positive and half negative labels, so if we predict 0 or 1 for everything we should get half of them correct.
The accuracy score is on a 0-1 scale where 1 means 100% accuracy
2.4.1.1 Imbalanced datasets and accuracy
Metrics are not foolproof. What is “good” for one dataset may not be for another. This is why we start with the simplest possible model. Because it allows us to establish minimum benchmarking values to compare against. Let’s run through an example to show how accuracy changes with the ratio of positive to negative labels in the dataset using this simple model.
I love
seaborn for rapid data visualization. It can’t do everything perfectly, but it does the common things beautifully.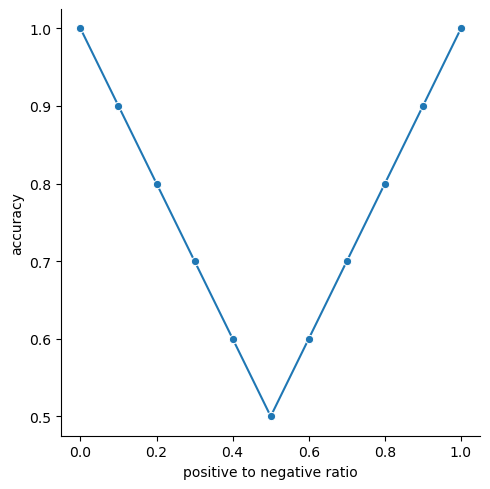
The accuracy of our model is 50% when we have a 50/50 ratio of positive to negative labels. As the ratio moves to either extreme however (all ones or all zeros), the accuracy goes up until it reaches 100% when all the labels in the dataset are the same.
Intuitively a higher accuracy is better, but it might not be high because your model works well. It could be that your dataset is imbalanced and your model has figured that out and predicts everything to be the majority class. In that scenario, you end up with a fancy model you put all this effort into just to get the same result as the simple model we just made. How do you combat this? By doing what we’ve done here and start with a simple model. Then as you develop more complex models, they can be compared to this simple model to see if they make improvements!
2.4.2 Other metrics
Accuracy is not the only thing we can measure, but for simplicities sake it will be the only thing we measure in this book. Other common metrics we could look at are F1-score and Matthews Correlation Coefficient (MCC), but there’s plenty more.
2.5 Train vs. test datasets
We’ve trained a model and evaluated it’s accuracy so now we can move on to making a better model. WRONG, WE HAVEN’T EVALUATED THE MODEL!!! We checked the accuracy on the training data which isn’t a true evaluation of the model. We want to know how well our model works on data it hasn’t seen yet, which is why we have a test set. The test set is used exclusively to benchmark the performance of the model and is not used in the training process. This comes back to making models that generalize to unseen data. Models generally perform better on data they’re trained on because that data is what the model is optimized to predict for. If we use that same data to test the model, then we’ll likely be overconfident in our models predictions. When we deploy the model and it is used on new data it hasn’t seen we’ll be in for a rude awakening. So we separate our dataset into training and testing datasets. In practice care should go into how these datasets are curated, but we won’t worry about that here since I’ve already cleaned our datasets.
I highly recommend this blog post on the dangers of blindly splitting your data. It is about validation sets, but the same concepts apply to test sets.
So let’s evaluate our model for real.
0.5011190233977619The accuracy is still 0.5 which makes sense. The test dataset is curated the same way as the train dataset and has a roughly 50/50 split of positive to negative labels. While the accuracy didn’t change between the train and test datasets, we have a more unbiased evaluation of our model and this is the accuracy we will aim to beat next.
2.6 Preprocessing
When we prepared our training data, we ran this code:
All we did was pull out the relevant columns from the dataframe, which is as simple as it gets. Preprocessing can get very complicated and we’ll explore how preprocessing impacts model performance in future chapters. One important aspect of preprocessing is the test dataset needs to be preprocessed the same way as the train dataset, because the model expects the data it makes predictions about to have the same form as the data it was trained on.
2.7 Rolling our own
Now that we’ve trained a model, let’s make it ourselves. It’s as simple as you can get, majority rules. We need to find the unique labels, count them, and keep the label with the highest count. np.unique gives us all the information we need.
(array([0, 1]), array([12432, 12472]))This shows the positive label is the majority class. Does this line up with the sklearn baseline?
Earlier I said models are just equations and that’s true of this model. It’s just the equation
f(x) = 1np.True_Yes it does! Congratulations, you’ve just implemented a machine learning model from scratch.
2.8 scikit-learnifying our model
scikit-learn provides a framework to integrate your own machine learning models to leverage all the bells and whistles provided by their API. One such benefit is benchmarking. scikit-learn models come with a score method, and the default score method for classifiers is accuracy. By wrapping our model in scikit-learns framework, we get accuracy scores (and a bunch of other stuff) for free.
2.8.1 scikit-learn best practices
There’s a pretty lengthy document on developing scikit-learn models, but most of the advice on that page can be boiled down to a few points.
If you get serious about making
scikit-learn estimators read that document closely.__init__is for setting attributes, not computation.- Every parameter for
__init__should have a corresponding attribute. - Computation during training that needs to persist across method calls should be assigned to attributes with an underscore suffix.
- The
fitmethod is for training and thepredictmethod is for prediction. fitshould returnself.BaseEstimatorshould be to the right ofscikit-learnmixins.- Classifiers should have a
classes_attribute with the unique labels in the training set. - Must accept
Ndata points at once.
A note on that last point, accepting multiple data points at once comes with two benefits.
- Multiple data points can be predicted at once.
- Operating on multiple data points at once allows for leveraging highly optimized libraries, like
numpy, for improved speed.
With a few tweaks, our BaselineClassifier becomes a scikit-learn model.
from sklearn.base import BaseEstimator, ClassifierMixin
class BaselineClassifier(ClassifierMixin, BaseEstimator):
def fit(self, X, y):
"""Train the model with inputs `X` on labels `y`."""
# Get the unique labels and their counts.
self.classes_, counts = np.unique(y, return_counts=True)
# Keep the most common label for prediction.
self.prediction_ = self.classes_[np.argmax(counts)]
return self
def predict(self, X):
"""Predict the labels for inputs `X`."""
# Return the most common label as the prediction for every
# input.
return np.full(len(X), self.prediction_)
cls = BaselineClassifier().fit(X, y)
cls.score(X_test, y_test)0.5011190233977619And with that we get accuracy for free. Thanks scikit-learn.
We’ve built our first model and tested it’s accuracy on an independent test set. This is the score we’ll aim to beat next chapter as we begin adding complexity.